JPA 객체 간 연관 관계 매핑
Table of contents
다 대 1 연관관계 매핑
ManyToOne 과 OneToMany
Member 와 Team 은 1대 다 관계라고 볼 수 있다.
한 팀은 여러명의 회원들을 가질 수 있고, 회원은 하나의 팀만 갖을 수 있기 때문이다.
Member 의 기본키 변수명 member_id, Team의 기본키 변수명 team_id 라고 가정하고 연관관계 매핑을 해보겠다.
//Member 측
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
//Team 측
@OneToMany(mappedby = "team")
private List<Member> members = new ArrayList<>();
ManyToOne 은 맴버 한명은 팀 하나를 갖기 때문에, Team 이라는 객체로서 맴버로 사용할 수 있다.
하지만, Team의 경우 여러명의 Member 를 갖기 때문에, List<Member> 로서 맴버를 갖고 있다.
1대 다 관계에서, 1측은 객체를 참조할때, @JoinColumn(name = "다 측 기본키 변수명") 을 통해서, 어떤 기본키로 연관관계가 맺어져 있는지 명시해야한다.
다측은 1측에서 어떤 변수명으로 매핑이 되어있는지 @OneToMany(mappedby = "참조되어있는 변수명") 으로 명시해주어야 한다.
참고로
XToOne관계는 기본값이FetchType.EAGER로 되어있어, 성능 최적화와 자원 낭비 방지를 위한 지연로딩을 위해FetchType.LAZY를 해두어야 한다.
XToMany는 기본값이FetchType.LAZY로 되어있어 따로 명시하지 않아도 된다.
이로써 Member에서 Team을 사용할 수 있고, Team에서 Member를 사용할 수 있는 양방향 연관관계를 맺었다.
양방향 관계를 맺었을 시 한쪽 객체의 데이터 변경 시 양쪽에 변화를 반영할 수 있도록 연관관계 편의 메서드를 작성해두는 것이 좋다.
DB에 쿼리문이 전달되면 상관없지만, 트랜잭션이 끝나기 전에 결과가 반영되지 않은 영속성 컨텍스트에서 mapped by 된 컬렉션을 사용할 수도 있기 때문이다.
연관관계 메서드는 보통 외래키를 사용하는 쪽, 연관관계를 컬렉션이 아닌 객체로 갖고 있는 엔티티에서 갖고 있는 것이 좋다.
// team_id 외래키를 사용하는 Member 측에 연관관계 메서드 작성
//====연관관계 편의 메서드==//
public void changeTeam(Team team){
this.team = team;
team.getMembers.add(this);
}
1 대 1 연관관계 매핑
OnetoOne
다 대 1 관계와 구현은 비슷하지만, 외래키에 유니크 제약조건을 추가한다. ( 1대 1을 유지하려고)
양쪽 다 @OneToOne 어노테이션을 사용하고, 연관관계 주인인 객체에는 @JoinColumn 을 추가한다.
// Member 가 연관관계 주인
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "member_id")
private Long id;
private String name;
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name= "locker_id")
private Locker locker;
}
//Locker 클래스는 mapped by
@Entity
public class Locker {
@Id
@Column
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToOne(mappedBy = "locker")
private Member member;
}
다 대 다 연관관계 매핑
다 대 다 관계 테이블은 관계테이블을 추가해서 다 대 1 , 1 대 다 관계로 풀어내야 한다.
(@ManyToMany 어노테이션이 있지만 쓰지 않는 것이 좋다.)
즉, ManyToMany 관계를 중간에 테이블을 추가해서 ManyToOne, OneToMany 로 연결되게끔 만드는 것이다.
상속관계 매핑
상속관계 매핑은 총 3가지 전략이 있다.
부모 클래스에서 @Inheritance 어노테이션을 사용하면 되고, 3가지의 전략 중 하나를 선택할 수 있다.
@Entity
@Inheritance(strategy = InheritanceType.XX)
public class Parent {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long parentId;
private String parentName;
}
@Entity
public class Child extends Parent {
private String childName;
private String chileAge;
}
위와 같은 상속 관계인 객체가 있다고 가정해보고 결과를 확인해보겠다.
1. 조인전략 (starategy = InheritanceType.JOINED)
각 자식 테이블은 부모 테이블의 기본키를 갖고 있다.

조인 전략 결과는 위와 같이, 자식 테이블은 부모테이블의 기본키를 갖고 있다.
위와 같이 테이블을 생성하면, child 객체에서 parent 맴버들을 사용할 수 있으므로 아래와 같이 데이터를 입력할 수 있다.
Child child = new Child();
child.setChildName("son");
child.setChileAge("1");
child.setParentName("mom");
em.persist(child);
결과를 확인해보면, parent 테이블에도 데이터가 잘 입력된 것을 확인할 수 있다.
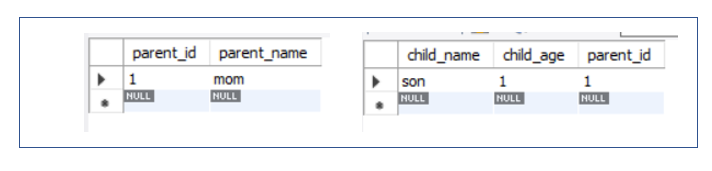
하지만, 위와 같은 상황에서 parent 테이블만 봤을때, 저 데이터가 어떤 자식 테이블과 연관되어있는지 확인하기 어렵다.
이러한 경우 사용할 수 있는 어노테이션이 @DiscriminatorColumn 이다.
@Entity
@Setter
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn
public class Parent {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "parent_id")
private Long parentId;
@Column(name = "parent_name")
private String parentName;
}
@Entity
@Setter
//@DiscriminatorValue("원하는 구분명")
public class Child extends Parent {
@Column(name = "child_name")
private String childName;
@Column(name = "child_age")
private String chileAge;
}
자식 객체에는 @DiscriminatorValue 어노테이션을 활용하여 원하는 구분명을 작성할 수 있고, 따로 명시하지 않으면 엔티티 명으로 입력된다.
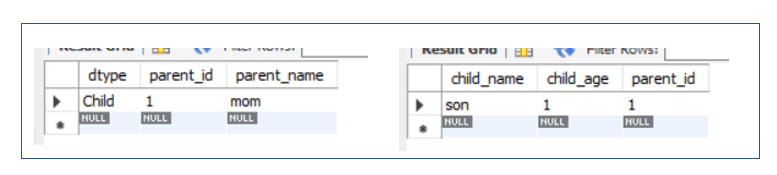
위와 같이 dtype 이라는 속성명으로 표시해준다. @DiscriminatorColumn(name = "원하는 구분 속성 명") 으로 속성명도 지정할 수 있다!
테이블이 정규화 되어있는 큰 장점이 있고, 저장 공간이 효율적이다.
하지만, 조회 시 조인 쿼리를 사용해야하는 단점이 있다.
2. 단일 테이블 전략 (strategy = InheritanceType.SINGLE_TABLE)
부모 테이블과 자식 테이블의 속성을 모두 합쳐서 하나의 테이블로 만든다. 그리고 자식 객체를 구분할 수 있는 속성을 추가해서 사용한다.
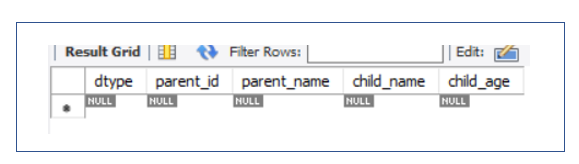
위와 같이, 자식 객체의 테이블은 생성되지 않고, 부모 엔티티를 기준으로 자식 객체의 모든 맴버들을 합쳐서 한 테이블로 만든다.
단일테이블 전략의 경우, DiscriminatorColumn 이 꼭 적용되어 있어야, 자식 객체들 끼리 구분할 수 있다.
그래서인지, @DIscrimminatorColumn 어노테이션을 생략해도, JPA가 입력해준다.
단일테이블 전략은, 한 테이블에 존재하는 속성과 튜플들의 갯수가 많아질 수 있지만, 조회나 입력 시 쿼리문을 하나만 실행시켜도 된다는 이점이 있다.
참고로 전략을 명시하지 않으면, 단일 테이블 전략은 JPA의 기본 전략이다.
3. 구현 클래스마다 테이블 전략 (strategy = InheritanceType.TABLE_PER_CLASS)
자식 테이블 각각이 부모 테이블의 모든 속성과 데이터를 보관한다.
Cannot use identity column key generation with <union-subclass>
참고로, 이 전략은 @GeneratedValue(strategy = GenerationType.IDENTITY) 를 기본키 전략으로 사용하면 위와 같은 에러가 발생할 수 있어 AUTO 로 변경해야한다.
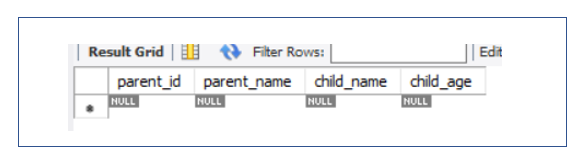
만들어진 자식 테이블을 보니, 부모의 모든 속성을 갖고 있음을 알 수 있다.
따라서, 각 테이블마다 속성 갯수가 늘어나고, 조회나 입력 시에도 쿼리문이 여러개 필요하므로 큰 이점이 존재하지 않는다.
직관적으로 봤을 때는, 자식 테이블에 부모 테이블에 있어야 할 정보들이 있어 편리해 보이지만,
em.find(부모클래스,기본키) 와 같이 부모 클래스로 조회할 때, 모든 자식 테이블을 union 해버려서 성능이 저하된다는 큰 단점이 있다.
따라서, 조인 전략이나 싱글테이블 전략 둘 중에 상황에 맞춰 사용하는 것이 바람직하다.
4. @MappedSuperclass
@MappedSuperclass 어노테이션을 명시한 객체를 상속하면, 그 객체가 갖고 있는 변수가 마치 @Embeddable 을 사용했을 때와 비슷한 기능을 수행한다.
@Embeddable 과의 차이점은, 참조할때 드러난다.
💡💡💡
@Embeddable 의 경우 참조할때, 엔티티.임베디블객체.임베디블객체변수 와 같은 방법으로 사용할 수 있지만
@MappedSuperclass 의 경우, 엔티티가 변수의 묶음인 객체를 갖는 것이 아닌, 변수 하나하나를 갖기 때문에, 엔티티.상속받은변수 와 같은 방법으로 사용할 수 있다.
참고로,
@Embeddable클래스를@Embedded해서 사용할 때, 같은 임베디드 클래스를 한 객체에서 중복해서 사용할 일이 있는 경우
@AttributeOverrides어노테이션을 추가로 붙여준 뒤`@AttributeOverride(name=”임베디블 클래스 변수명”,column=”테이블에서 사용할 속성명”) 으로 재정의 해서 사용해야한다.